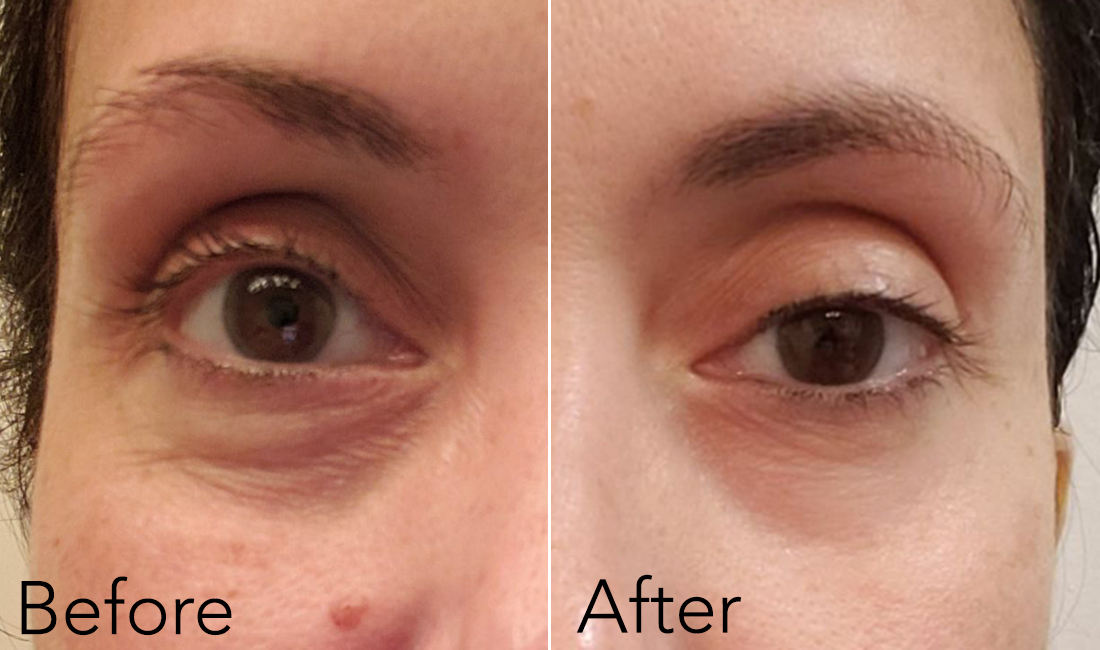
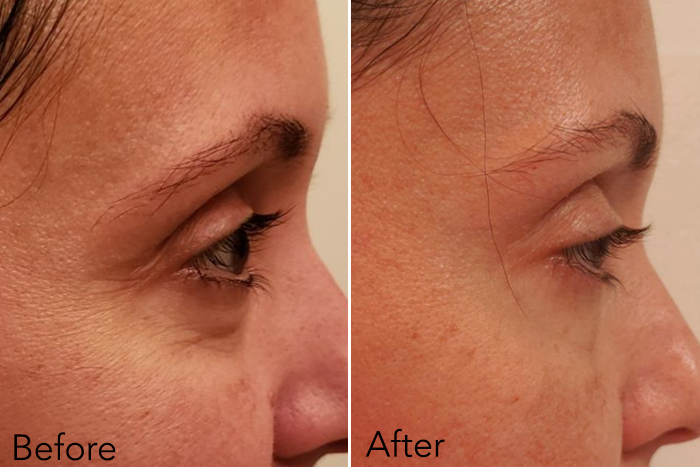
Eye cream or Photoshop? After using the Swanicoco Fermentation Peptine Eye Care Cream for one month, one woman watched her fine lines smooth out and her undereye bags and dark circles nearly disappear. Follow her journey below, and learn more about the benefits of fermented ingredients, including our top product picks that incorporate them.
Elke, 48, was never a big fan of eye creams. “I was never motivated to continue use much after two weeks since there were never any visible changes,” she told us.
If there were any formula up for the challenge of turning Elke into an eye cream convert, it’d be the Swanicoco Fermentation Peptine Eye Care Cream, a product that was crowned the top-performing anti-aging formula in Korea in 2018.
The formula contains eight patented peptides – ingredients that can boost collagen and elasticity – in addition to adenosine, niacinamide, and hyaluronic acid to firm, plump, brighten, and hydrate. It also contains K-beauty’s popular anti-aging ingredient, wild ginseng root, and EGF (Epidermis Growth Factor) that work to protect and rejuvenate your skin.
Further, this eye cream was developed with a special fermentation process, breaking down these efficacious ingredients to allow for better skin penetration and absorption around the delicate eye area.
RELATED: Why Your Eye Cream Isn’t Working
We tasked Elke with using the product twice a day for one month. Read on below to learn about her experience. 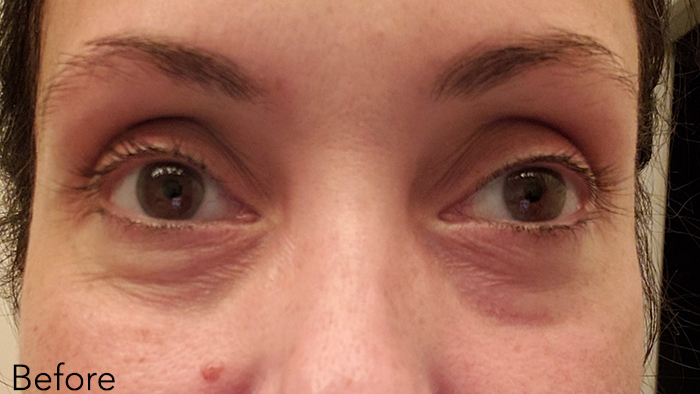
What were your first impressions of the eye cream?
It wasn’t heavy and it felt soft and silky both on my fingers and around my eyes. There was no tingling or irritation when I applied the product. When putting it on in the morning, it seemed to absorb pretty quickly which was helpful since my prep time before leaving the house is only a half hour.
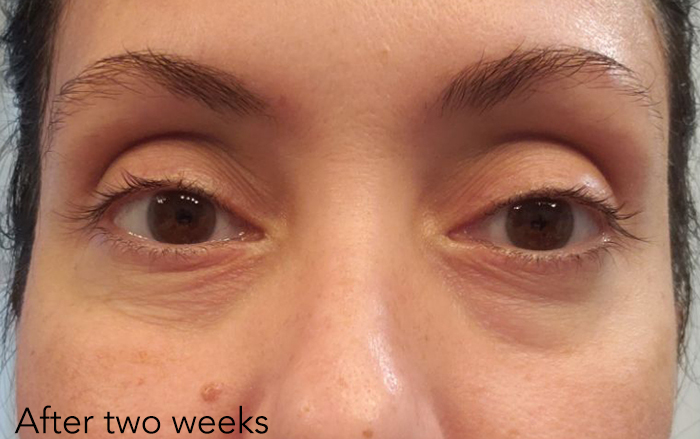
How quickly did you start to see results?
Two days after starting the eye cream a friend commented that I looked different, that my eyes looked more rested. She had not known that I was testing the eye cream.
What results did you see after four weeks of use?
After four weeks the results are huge. I don’t get much sleep and I’m in front of a computer screen all day, every day. Even with a lack of rest and with continual eye strain, the eye cream has helped my eyes look less puffy and less tired in four weeks. I can just imagine how much better the results would be if I got more sleep.
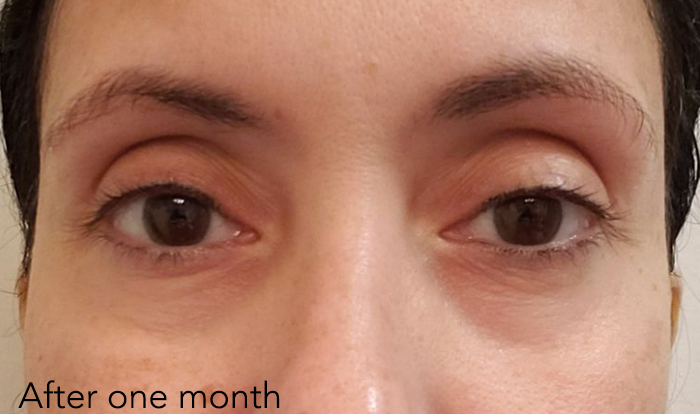
Any final thoughts?
I don’t use any makeup or foundation. I’m sure if I did my eyes would look even smoother with this cream as the initial base. But this cream makes me feel even better accepting my natural skin and letting it shine.
Fermented ingredients: Our top product picks
Just like how fermented foods aid digestion, fermented ingredients in skin care reap many benefits. Fermentation not only helps ingredients absorb faster into the skin, but it also helps boost the nutritional density of an ingredient, increasing the effectiveness of the product.
Below are some of our favorite products with fermented ingredients:
Then I Met You™ The Giving Essence: This essence has a luxurious list of ingredients that help hydrate, brighten, and revitalize the skin in one step. More than 80% of its formula contains naturally fermented ingredients like galactomyces ferment filtrate and saccharomyces ferment filtrate, which help reduce the appearance of sebum, pores and blackheads.
Beauty of Joseon Radiance Cleansing Balm: Formulated with soybean ferment extract, nutrient-rich rice bran water and Korean herbal medicine, this cleansing balm not only melts away impurities, makeup and excess oil, but it also helps the skin retain moisture and brighten the skin. While it contains powerful ingredients, it has a soothing, sherbert-like texture that cleanses without irritating the skin.
Son Reve Tri-Bio Treatment Essence: Boasting a clean but nutrient-packed formula of 90% fermented ingredients such as rice ferment filtrate and galactomyces ferment filtrate, this treatment essence has amazing skin brightening benefits while hydrating and revitalizing the skin.














